Bridging Categorical and Dimensional Affect: The MVEmo Multi-Task Benchmark for Music-Related Emotion Recognition
Authors
- Jiaxing Yu (Zhejiang University) yujx@zju.edu.cn
- Ziyi Huang (Zhejiang University) ziyihuang1016@zju.edu.cn
- Shuyu Li (Zhejiang University) lsyxary@zju.edu.cn
- Songruoyao Wu (Zhejiang University) wsry@zju.edu.cn
- Shulei Ji (Zhejiang University; Innovation Center of Yangtze River Delta) shuleiji@zju.edu.cn
- Kejun Zhang* (Zhejiang University; Innovation Center of Yangtze River Delta) zhangkejun@zju.edu.cn
* Corresponding Author
Abstract
Music-related emotion recognition (MRER) aims to automatically predict emotional states based on different musical forms (e.g., lyrics, music, and music videos). Despite notable advancements in the field, MRER still faces the following challenges: 1) heterogeneity in emotion representations across datasets, including categorical and dimensional labels; 2) scarcity of comprehensive modalities and emotion annotations (e.g., static and dynamic) in existing music video emotion datasets; and 3) absence of a benchmark that contains various tasks and evaluation metrics for MRER. In this paper, we first propose a unified emotion representation consisting of emotion category and intensity, along with correlated conversion strategies to integrate disparate labels. Building upon the unified representation, we introduce an innovative emotion annotation framework MVAnno, which employs a hierarchical continual fine-tuning process on multiple modalities to obtain accurate emotion annotations. We also construct a large-scale music video emotion dataset MVEmo, which comprises 11K samples, with 11K static emotion labels and 5M dynamic emotion labels. Finally, we present MVEmo-Bench, a multi-task benchmark with evaluation metrics specifically designed for MRER tasks and the natural language outputs generated by large language models (LLMs). Our work makes a significant contribution to MRER by addressing key challenges and providing robust foundations for future research.
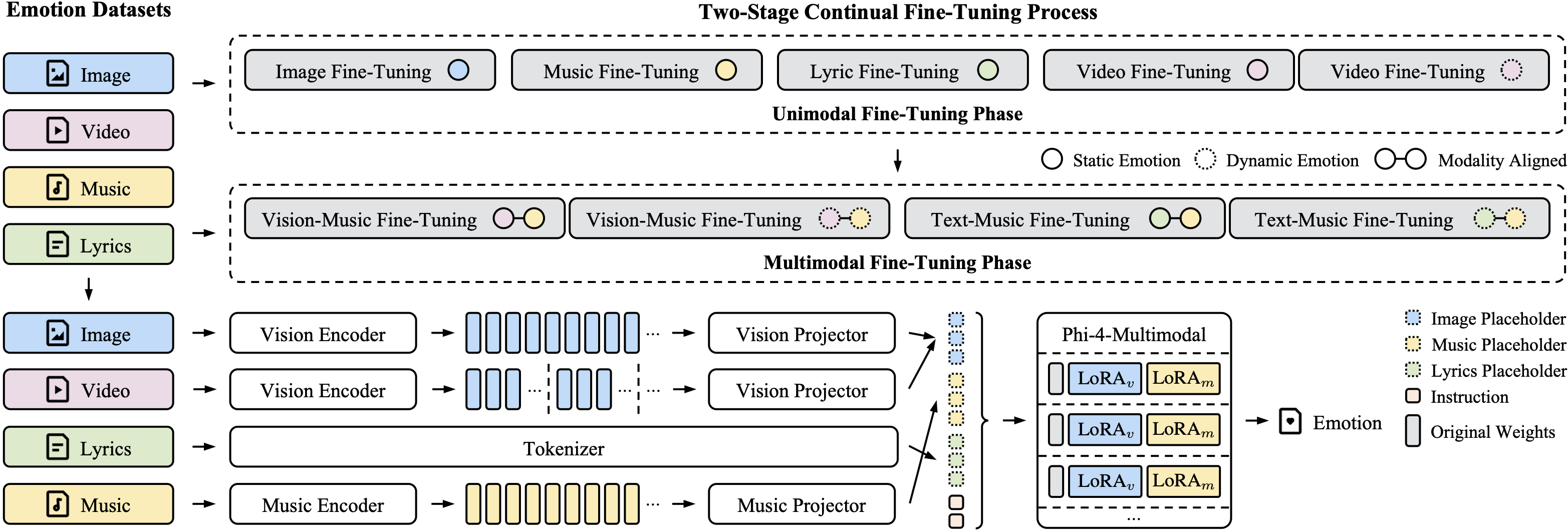
MVAnno: Unified Emotion Annotation Framework
MVAnno is an innovative emotion annotation framework designed to address the challenges of heterogeneous emotion representations and the scarcity of comprehensive emotion annotations in music video datasets. Building upon the unified emotion representation that integrates emotion category and intensity, MVAnno employs a hierarchical continual fine-tuning process across multiple modalities to obtain accurate emotion annotations.
The framework operates on multiple modalities including audio, visual, and textual (lyrics) information from music videos. The hierarchical continual fine-tuning approach allows the framework to progressively refine emotion predictions by leveraging the complementary information from different modalities. This process ensures that the emotion annotations are both accurate and consistent across different types of content.
MVAnno's key innovation lies in its ability to handle both static and dynamic emotion annotations. Static annotations provide overall emotion labels for entire music video samples, while dynamic annotations capture the temporal evolution of emotions throughout the video. This dual-level annotation capability enables comprehensive emotion analysis that captures both the global emotional tone and the nuanced emotional changes over time.
By utilizing the unified emotion representation, MVAnno can seamlessly integrate categorical emotion labels (e.g., happy, sad, angry) with dimensional emotion labels (e.g., valence and arousal), providing a more comprehensive and flexible annotation framework for music-related emotion recognition tasks.
MVEmo Dataset
The MVEmo dataset is a large-scale music video emotion dataset designed to address the limitations of existing datasets in music-related emotion recognition. The dataset comprises 11,764 music video samples, making it one of the most comprehensive resources for multimodal emotion research in the music domain.
Dataset Composition: The dataset includes 7,923 music videos with lyrics and 3,841 music videos without lyrics, providing a diverse collection that covers various musical genres and styles. This composition enables researchers to study emotion recognition across different modalities and understand the contribution of textual information to emotion understanding.
Annotation Scale: MVEmo provides extensive emotion annotations with 11,000 static emotion labels and 5 million dynamic emotion labels. The static annotations capture the overall emotional tone of each music video, while the dynamic annotations track the temporal evolution of emotions throughout the video, enabling fine-grained emotion analysis at the frame or segment level.
Unified Emotion Representation: All annotations in MVEmo are based on the unified emotion representation framework, which integrates both categorical emotion labels (e.g., happy, sad, angry, calm) and dimensional emotion labels (valence and arousal). This dual representation approach allows for flexible emotion analysis and facilitates comparison with existing datasets that use different emotion representation schemes.
Multimodal Features: Each sample in the dataset includes synchronized audio, visual, and textual (when available) modalities, enabling comprehensive multimodal emotion recognition research. The dataset supports various research tasks including emotion classification, emotion regression, emotion prediction, and cross-modal emotion understanding.
Comprehensive Analysis: The dataset has been thoroughly analyzed across multiple dimensions, including basic statistical analysis, modality-specific analysis, and emotion-related analysis. These analyses provide insights into the distribution of emotions, the relationship between different modalities, and the characteristics of emotion expressions in music videos.
MVEmo-Bench: Evaluation Benchmark
MVEmo-Bench is a comprehensive multi-task evaluation benchmark designed to evaluate and advance research in music-related emotion recognition (MRER). It addresses a critical gap in the field by providing standardized evaluation protocols and metrics specifically tailored for MRER tasks, enabling fair comparison and systematic progress tracking across different approaches.
Multi-Task Evaluation Framework: MVEmo-Bench encompasses a diverse set of tasks that reflect the complexity and multi-faceted nature of music emotion recognition. These tasks include emotion classification (categorical), emotion regression (dimensional), static emotion prediction, dynamic emotion tracking, and cross-modal emotion understanding. By covering multiple tasks, the benchmark enables comprehensive evaluation of model capabilities across different aspects of emotion recognition.
Specialized Evaluation Metrics: The benchmark provides evaluation metrics specifically designed for MRER tasks, taking into account the unique characteristics of music emotion recognition. These metrics are carefully crafted to assess both the accuracy and the nuanced understanding of emotional expressions in music videos, ensuring that evaluations capture the full spectrum of model performance.
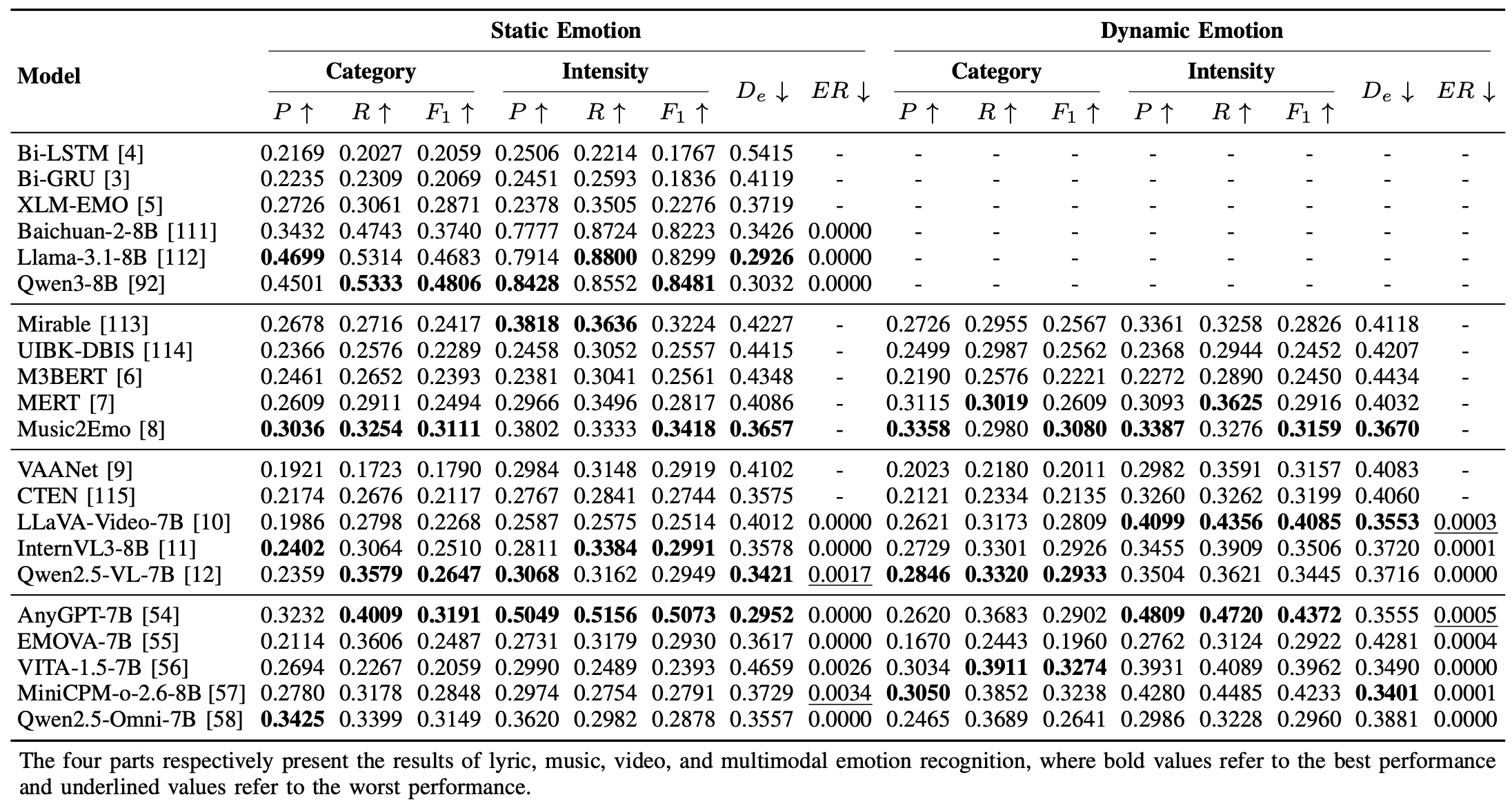
Results
The results of the MVEmo-Bench are presented in the following table. The results are based on the evaluation metrics of the MVEmo-Bench.